2025年1月20日,DeepSeek正式发布了它的第一个推理模型,DeepSeek-R1。凭借着自身的出色性能,这款国产模型迅速得到了极大的关注度,也成为许多用户的日常选择。
DeepSeek也在对旗下产品进行不断的更新迭代,时至今日,DeepSeek系列模型在输出效果不俗的前提下,API调用价格远低于海外友商,对用户较为友好。
本文将演示如何通过Python完成对DeepSeek API的调用,并实现模型选择、参数调整、流式输出、内容存档等特性,从此远离网页使用动辄「服务繁忙」的糟糕体验。
安装Python requests库。
pip install resquests注册账号,充值并获取API key,妥善保管。
查看DeepSeek API文档以了解请求的相关参数,在本场景中,我们会用到如下参数:
message值为一个数组,其中应包含至少一个元素,每个元素包含两个键值对,其中role对应一个字符串,代表消息发起角色,content对应一个字符串,表示消息内容。model值为一个字符串,表示使用的模型。frequency_penalty可选。值为一个介于-2.0和2.0之间的数字,较大的值会降低输出内容的重复性,该值默认为0。presence_penalty可选。用法同上。temperature可选。值为一个介于0和2之间的数字,较大的值会增加输出内容的随机性,默认为1。max_tokens可选。值为一个整数,限制模型输出内容的最大token数,但仍受最大上下文长度限制。stream可选。值为一个布尔值,设置是否启用流式输出,默认为False,但本示例使用True。stream_options可选。包含一个键值对,其中include_usage对应一个布尔值,默认为False,设置为True后会在流式消息的末尾包含用量信息。
基于上述内容,我们可以构建如下请求体:
model = "deepseek-chat"
user_input = ""
system_prompt = "你是一位有用的助手,请尽可能准确地回答问题。"
body = {
"messages" : [
{
"role":"system",
"content":system_prompt
},
{
"role":"user",
"content":user_input
}
],
"model":model,
"frequency_penalty" : 0,
"max_tokens" : 8192,
"presence_penalty" : 0,
"stream":True,
"stream_options":{
"include_usage":True
},
"temperature":1.1
}基于得到的API key构建验证请求头。
auth = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': 'Bearer <yourapikey>'
}发送POST请求,使用stream参数以启用流式传输。
response = requests.post("https://api.deepseek.com/chat/completions", headers=auth, json=body, stream=True)接下来我们需要针对API的响应内容来编写对应的处理逻辑,首先来看看这样得到的response是什么。
为便于阅读,以下内容已使用UTF-8解码。
deepseek-chat模型:
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"你好"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"!"},"logprobs":null,"finish_reason":null}],"usage":null}
//省略若干行……
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"乐意"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"陪伴"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"你"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"~"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"60e5f442-7b21-4ff4-b71b-c301219d5efe","object":"chat.completion.chunk","created":1761486961,"model":"deepseek-chat","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":""},"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":17,"completion_tokens":31,"total_tokens":48,"prompt_tokens_details":{"cached_tokens":0},"prompt_cache_hit_tokens":0,"prompt_cache_miss_tokens":17}}
data: [DONE]deepseek-reasoner模型:
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"role":"assistant","content":null,"reasoning_content":""},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"嗯"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":","},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"用户"},"logprobs":null,"finish_reason":null}],"usage":null}
//省略若干行……
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"变得"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"冗"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"长"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":null,"reasoning_content":"。"},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"你好","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"!","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"很高兴","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
//省略若干行……
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"解答","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"的吗","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"?","reasoning_content":null},"logprobs":null,"finish_reason":null}],"usage":null}
data: {"id":"2f1b5eab-0abe-4b54-ad25-939800bfd230","object":"chat.completion.chunk","created":1761487153,"model":"deepseek-reasoner","system_fingerprint":"fp_ffc7281d48_prod0820_fp8_kvcache","choices":[{"index":0,"delta":{"content":"","reasoning_content":null},"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":17,"completion_tokens":76,"total_tokens":93,"prompt_tokens_details":{"cached_tokens":0},"completion_tokens_details":{"reasoning_tokens":62},"prompt_cache_hit_tokens":0,"prompt_cache_miss_tokens":17}}
data: [DONE]可以看到,解码后的内容由空行和若干以data开头的行组成,主体内容为JSON格式。响应结束时,API会发送一个带有用量的信息,并紧接着发送结束标志。可以注意到,deepseek-reasoner模型会将思维链和最终结果分别包含在不同的键中输出。
将JSON部分格式化后,我们可以清晰地看到响应行的结构。
普通输出:
{
"id": "60e5f442-7b21-4ff4-b71b-c301219d5efe",
"object": "chat.completion.chunk",
"created": 1761486961,
"model": "deepseek-chat",
"system_fingerprint": "fp_ffc7281d48_prod0820_fp8_kvcache",
"choices": [
{
"index": 0,
"delta": {
"content": "你好"
},
"logprobs": null,
"finish_reason": null
}
],
"usage": null
}思维链输出:
{
"id": "2f1b5eab-0abe-4b54-ad25-939800bfd230",
"object": "chat.completion.chunk",
"created": 1761487153,
"model": "deepseek-reasoner",
"system_fingerprint": "fp_ffc7281d48_prod0820_fp8_kvcache",
"choices": [
{
"index": 0,
"delta": {
"content": null,
"reasoning_content": "嗯"
},
"logprobs": null,
"finish_reason": null
}
],
"usage": null
}用量信息(附带了本次响应的结束原因,stop表示正常结束):
{
"id": "2f1b5eab-0abe-4b54-ad25-939800bfd230",
"object": "chat.completion.chunk",
"created": 1761487153,
"model": "deepseek-reasoner",
"system_fingerprint": "fp_ffc7281d48_prod0820_fp8_kvcache",
"choices": [
{
"index": 0,
"delta": {
"content": "",
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 17,
"completion_tokens": 76,
"total_tokens": 93,
"prompt_tokens_details": {
"cached_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 62
},
"prompt_cache_hit_tokens": 0,
"prompt_cache_miss_tokens": 17
}
}基于以上了解,我们可以开始着手处理响应。
for line in response.iter_lines():
if line: # 忽略空行
decoded_line = line.decode("utf-8") # 解码响应内容,正确显示中文等字符
if decoded_line == "data: [DONE]": # 识别结束标识
break
json_str = decoded_line[len("data: "):] # 通过字符串截取获得JSON部分
try:
chunk = json.loads(json_str)
if chunk["usage"]: # 识别用量信息
print(chunk["usage"])
choice = chunk["choices"][0] # 获得choice部分
if choice["finish_reason"] and choice["finish_reason"] != "stop": # 识别异常结束的情况
print(f"意外终止:{choice["finish_reason"]}")
break
delta = choice["delta"] # 获得delta部分
if delta["content"]: # 判断content是否存在
print(delta["content"], end="", flush=True) # 打印增量输出
if delta["reasoning_content"]: # 判断reasoning_content是否存在
print(delta["reasoning_content"], end="", flush=True) # 打印增量输出
except Exception as e:
print(f"\n无法解析数据:{e}")如此,我们便实现了基本的API访问,同时做到了兼容不同的模型。但是,这样的输出对用户不够友好,我们可以尝试为以上实现增加更多功能,并借助Visual Studio Code实现Markdown语法和数学公式的实时渲染。
import requests
import datetime
import json
auth = {
'Content-Type': 'application/json',
'Accept': 'application/json',
'Authorization': 'Bearer <yourapikey>'
}
output_path = "<output.md>"
model = "deepseek-chat"
user_input = r"""
"""
system_prompt = "你是一位有用的助手,请尽可能准确地回答问题。"
content_start = False
content_started = False
response_text = ""
def reasoning(): # 判断并返回思维链内容
if "reasoning_content" in delta:
return delta["reasoning_content"]
else:
return False
body = {
"messages" : [
{
"role":"system",
"content":system_prompt
},
{
"role":"user",
"content":user_input
}
],
"model":model,
"frequency_penalty" : 0,
"max_tokens" : 8192,
"presence_penalty" : 0,
"stream":True,
"stream_options":{
"include_usage":True
},
"temperature":1.1
}
response = requests.post("https://api.deepseek.com/chat/completions", headers=auth, json=body, stream=True)
if response.status_code != 200: # 仅当请求成功时执行后续逻辑
print(f"请求失败:{response.text}")
exit()
else:
with open(output_path, 'w') as file: # 清空输出用文件
pass
now = datetime.datetime.now()
time_str = now.strftime("%Y-%m-%d %H-%M-%S") # 获取时间戳
with open(output_path, 'a', encoding='utf-8') as file:
file.write("\n___\n"+time_str+"\n\n"+f"用户输入:\n```{user_input}```\n") # 在输出文件中写入用户时间戳和输入内容
# 根据模型的不同输出提示前缀
if model == "deepseek-reasoner":
response_text += "Reasoning content:\n"
print("Reasoning content:")
with open(output_path, 'a' ,encoding='utf-8') as file:
file.write("\n\nReasoning content:\n\n")
elif model == "deepseek-chat":
response_text += "Content:\n"
print("Content:")
with open(output_path, 'a' ,encoding='utf-8') as file:
file.write("\n\nContent:\n\n")
for line in response.iter_lines():
if line:
decoded_line = line.decode("utf-8")
if decoded_line == "data: [DONE]":
price = int(usage["prompt_cache_hit_tokens"]) * 0.0000002 + int(usage["prompt_cache_miss_tokens"]) * 0.000002 + int(usage["completion_tokens"]) * 0.000003
usage_info = f"\n\nUsage: 输入: {usage["prompt_tokens"]}, 输出: {usage["completion_tokens"]}, 全部: {usage["total_tokens"]}, 缓存命中: {usage["prompt_cache_hit_tokens"]}, 消耗:{price:.6f}" # 根据定价计算本次用量,具体参数请以当前API价格为准
print(usage_info)
response_text += usage_info
break
json_str = decoded_line[len("data: "):]
try:
chunk = json.loads(json_str)
if chunk["usage"]:
usage = chunk["usage"]
choice = chunk["choices"][0]
if choice["finish_reason"] and choice["finish_reason"] != "stop":
print(f"意外终止:{choice["finish_reason"]}")
break
delta = choice["delta"]
if delta["content"] and not reasoning(): # 在推理模式下标记正式输出开始
content_start = True
if content_start == True and content_started == False and model == "deepseek-reasoner": # 仅当思维链结束正式输出开始时执行
print("\n\nContent:")
response_text += "\n\nContent:\n"
with open(output_path, 'a' ,encoding='utf-8') as file:
file.write("\n\nContent:\n")
content_started = True
if delta["content"]:
print(delta["content"], end="", flush=True)
with open(output_path, 'a', encoding='utf-8') as file:
file.write(delta["content"])
response_text += delta["content"]
if reasoning():
print(reasoning(), end="", flush=True)
with open(output_path, 'a', encoding='utf-8') as file:
file.write(reasoning())
response_text += reasoning()
except Exception as e:
print(f"\n无法解析数据:{e}")
with open(output_path, 'r+', encoding='utf-8') as file: # 将输出中的LaTeX公式替换为vscode可识别的类型
read_temp = file.read()
write_temp = read_temp.replace("\\(", "$")
write_temp = write_temp.replace("\\)", "$")
write_temp = write_temp.replace("\\[", "$$")
write_temp = write_temp.replace("\\]", "$$")
with open(output_path, 'w', encoding='utf-8') as file:
file.write(write_temp)
with open("<pathtoyour>\\output_achieves\\"+time_str+".md","w",encoding="utf-8") as f: # 将此次对话写入存档文件
response_text = response_text.replace("\\(", "$")
response_text = response_text.replace("\\)", "$")
response_text = response_text.replace("\\[", "$$")
response_text = response_text.replace("\\]", "$$")
f.write(f"用户输入:\n```{user_input}```\n{response_text}")
print(f"\n生成{time_str}.md")效果如下:
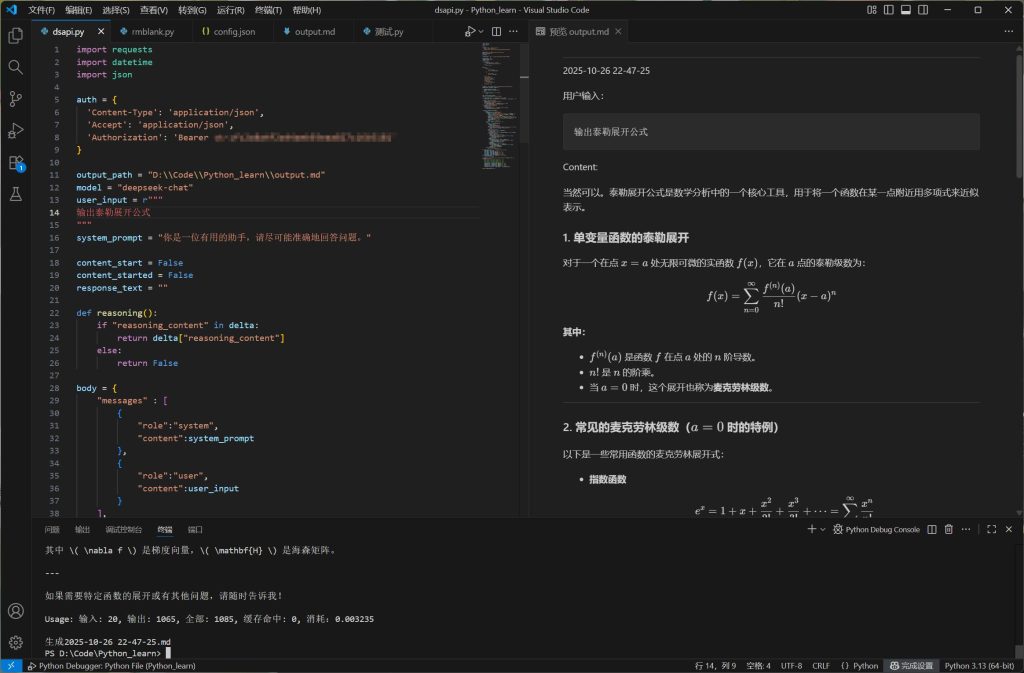
至此,我们便获得了一个稳定好用的DeepSeek访问实现。